
USAGE OF ONTOLOGIES IN SYSTEMS OF DATA EXCHANGE
ONTOLOĢIJAS LIETOŠANA DATU MAIŅU SISTEMĀS
P.Osipovs and A.Borisov
Keywords: Machine Learning, ontologies, semantic WEB, OWL, RDF, software agents, Attribute Value Taxonomies
This paper describes the methods and techniques used to effectively extract knowledge from large volumes of heterogeneous data. Also look at methods to structure the raw data by the automatic classification using ontology.
In the first part of the article the basic technologies to realize the Semantic WEB described. Much attention is paid to the ontology, as the major concepts that structure information on an unusually high level.
The second part examines AVT-DTL algorithm proposed by Jun Zhang, which allows automatically create classifiers according to the available raw, potentially incomplete data. The considered algorithm uses a new concept of floating levels of ontology and the results of the tests exceeds the best existing algorithms for creating classifiers.
Introduction
The complexity of the structure of the modern information society is constantly growing. In this regard, the requirements for effective processing algorithms also increase. General model of knowledge from raw data presented in Fig. 1. Recently the most popular trends in this area is Data Mining (DM), Knowledge Discovery in Databases (KDD) and Machine Learning (ML). They provide theoretical and methodological framework for studying, analyzing and understanding large amounts of data.
However, these methods are not enough if the structure of the data is so poorly suited for machine analysis, as historically to date on the Internet. Always there is a need to provide a convenient interface to access various data, provide an opportunity to consider them with a convenient point of view in such diverse areas as bio-informatics, e-commerce, etc.
To resolve this issue launched a global initiative of the restructuring of Internet data in order to transform it into the Semantic Web, which provides opportunities for efficient retrieval and analysis of data, both human and software agents. The most important part of the Semantic Web is the use of ontologies, which provide opportunities for presentation of some data in different points of view, on the needs and skills of their requests.
The major drawback of the existing structure of the Internet is that it practically does not use standards for the presentation of data easier to understand the computer, and all information is intended primarily for human consumption. For example, in order to get time family doctor, just go to the clinic site and find it in the list of all practicing physicians. However, if it is just to make a man, the software agent in the automatic mode it is virtually impossible unless you build it, subject to a rigid structure of a specific site.

Picture 1 Knowledge distillation process
To solve these problems using an ontology, describing any of the subject area in understandable terms for the machine and effective use of mobile agents.
Using this approach, in addition to the visible human data on each page, there are also ancillary data, allowing efficient use of data by software agents.
In turn, the ontology are part of a global vision of the Internet to a new level, called the Semantic WEB (SW) [1].
The most important concept of Semantic WEB
To achieve such a difficult goal as the global reorganization of the global network requires a set of interrelated technologies. Figure 2 provides the overall structure of the concepts of Semantic WEB. Below is a brief description of key technologies.
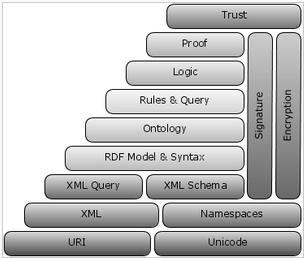
Picture 2 Stack of semantic web concepts
Semantic WEB
The concept of the semantic web is central to the modern understanding of evolution of the Internet. It is believed that the future data network will be presented in the usual form of pages, as well as metadata about the same proportion that will allow machines to use them for logical conclusions realizing the benefits from the use of methods of ML. Everywhere will be used Uniform Resource Identifiers (URI) and ontology.
However, not all so rosy, there are doubts about the full realization of the semantic web. Key Points for the benefit of doubt in the possibility of creating an efficient semantic web:
· The human factor [2], people can lie, lazy and add a meta description, use incomplete or simply incorrect metadata. As solution of this problem, automated tools to create and edit metadata can be used.
· Unnecessary duplication of information, where each document must have a full description of both the man and for the machine. This is partly solved by the introduction of microformats [3].
In addition to the metadata itself, the most important part of the SW is the semantic Web services. They are a source of data for agents, semantic web, originally designed to interact with the machines have a means of advertising their opportunities.
URI (Uniform Resource Identifier)
URI is a uniform resource identifier of any. May indicate both the virtual and the physical object. A unique character string overall, common structure which is represented in Figure 3. Currently the best-known URI for today is a URL, which is the identifier of the resource on the Internet and additionally contains information about the whereabouts of the addressed resource.
![]()
Picture 3 Base URI format
Ontologies
For the area under the Machine Learning ontology means a structure, conceptual framework for describing (formalizing) the values of some elements of the subject domain (SD). Ontology consists of a set of terms and rules describing their relationship.
Usually, ontologies are built from instances, the concepts of attributes and relationships.
· Instance - elements of the lowest level. The main purpose of ontology is precisely the classification of specimens, and although their presence in the ontology is not required, but usually they are present. Example: the word, the breed of animals, stars.
· Concepts - abstract sets, collections of objects.
Example: The concept of "stars" embedded the concept of "sun". What is the "sun", or the concept of nested instance (luminary) - depends on the ontology.
The concept of "luminary", a copy of "sun".
· Attributes - Each object can have an optional set of attributes allowing to store specific information.
Example: object "sun" has attributes such as:
Ø Type: yellow dwarf;
Ø Mass: 1.989 · 1030 kg;
Ø Radius: 695 990 km.
· Relationships - allow you to specify relationships between objects of the ontology.
So - as between different ontologies is possible to establish points of intersection, the use of ontologies allows us to look at one SD from different points of view and depending on the task to use different levels of detail considered SD. The concept of levels of detail of the ontology is a key, for example, to refer to the color signal lights sometimes simply specify a "green", while the description of color dyeing machines may not be sufficient even for such a detailed description as "dark green, similar in tone to the needles".
Consider the general structure of ontologies usages.
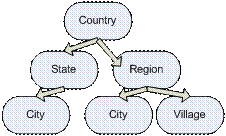
Picture 4 Part of the possible ontologies addresses
In the case of the ontology shown in Figure 4, in order to send a letter to an American university, it is sufficient to specify its name, a software agent finds its own address on the basis of a standard address information from the university, if you want to send a letter to a specific department, then with site will list all the faculties and the correct, and from the site required the faculty take the address, then using the above program will determine the format of the ontology addresses passed in the United States.
The computer does not understand all the information in the full sense of the word, but the use of ontologies allows him much more efficiently and intelligently use the available data.
Of course, many questions remain, for example, as in the beginning of the agent can find the desired site of the university? However, this is already developed tools. For example, an ontology language Network Services (Web Services Ontology Language, OWL-S [4]) which allows services to advertise their capabilities, services.
Fig. 5 shows a variant of the division of ontologies on the levels of formalization measure of how much of the ontological accuracy of each method.

Picture 5 Hierarchy taxonomies
Under the ontological accuracy of the ontology is understood to distinguish between shades of meaning.
· Catalog – contains a set of normalized terms without any hierarchical structure.
· Glossary – all terms are sorted in alphabetical order of natural language.
· Taxonomy – partially ordered collection of concepts (taxons) divides the subject domain from general to specific concepts.
· Axiomatised taxonomy – taxonomies subset contains certain axioms in a formal language.
· Context libraries / axiomatised ontologies – are interrelated set of axiomatised taxonomies. Is the intersection of several contexts, or the inclusion of one context to another.
Taxonomies
Taxonomies are one of the options for implementing ontologies. With the help of taxonomy may define the classes to which objects are divided into a certain subject area, and then, what relations exist between these classes. Unlike ontologies, taxonomies task is clearly defined within the hierarchical classification of objects.
Attribute Value Taxonomies (AVT)
An important example of the concept of taxonomy in Machine Learning is the concept Attribute Value Taxonomies.
Formal
definition of AVT. Suppose there is a vector of attributes ![]() , and
, and ![]() defines
a set of attribute values
defines
a set of attribute values ![]() . In this case, the formal definition of AVT is as
follows:
. In this case, the formal definition of AVT is as
follows:
Attribute
Value Taxonomies ![]() of attribute
of attribute ![]() a tree-like structure containing
a partially ordered hierarchy of concepts presented in the form of set
a tree-like structure containing
a partially ordered hierarchy of concepts presented in the form of set ![]() , where
, where ![]() is a finite set containing all
the attributes in
is a finite set containing all
the attributes in ![]() , and
, and ![]() is sign of a partial order defining the relationship
among the values of attributes in
is sign of a partial order defining the relationship
among the values of attributes in ![]() . Together,
. Together, ![]() represent an ordered set of
taxonomies of attribute values connected with
represent an ordered set of
taxonomies of attribute values connected with ![]() .
.
Let![]() presents a set of all values
presents a set of all values![]() , and
, and![]() points to the root element of the taxonomy
points to the root element of the taxonomy![]() . Set of leaves
. Set of leaves ![]() represent
all the primitive attributes
represent
all the primitive attributes ![]() . Тогда, абстрактными значениями атрибутов
. Тогда, абстрактными значениями атрибутов ![]() will be called the tree
will be called the tree ![]() . And every edge of the tree represents is-a
relation between the attributes of the entire taxonomy. Thus AVT defines an
abstract hierarchy between the values of attributes.
. And every edge of the tree represents is-a
relation between the attributes of the entire taxonomy. Thus AVT defines an
abstract hierarchy between the values of attributes.
Modern languages for ontologies describing
RDF (Resource Description Framework) [5] is a language for describing metadata resources, his main purpose is to present the allegations as equally well received by both human and machine.
Атомарным объектом в RDF является триплет: субъект – предикат – объект. Считается, что любой объект, можно описать в терминах простых свойств и значений этих свойств.
Table 1
Sample of table with selected parameters
|
:me |
:owns |
:my_appartment |
|
:me |
:owns |
:my_computer |
|
:me |
:is_in |
:philadelhia |
|
:my_appartment |
:has_a |
:my_computer |
|
:my_appartment |
:has_a |
:my_bed |
|
:my_appartment |
:is_next_to |
:my_bed |
Before the colon should be disclosed Uniform Resource Identifier (URI), but in order to save traffic is allowed to specify only the namespace.
Additionally, in order to improve the perception of human, there is the practice of representation of the RDF in the form of graphs.
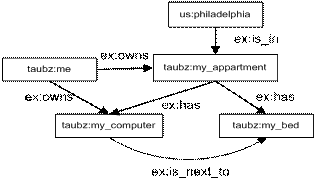
Picture 6 Example of presentation of RDF schema as a graph
In Fig. 6 shows an example presentation of the structure of RDF as a graph. Ribs are approved, the name at the beginning of the rib - subject to approval at the end of its addition, at the very name of the arc - the predicate.
OWL (Web Ontology Language)[6] is a web ontology language, created to represent the value of terms and relations between these terms in dictionaries. Unlike RDF, the language uses a higher level of abstraction that allows the language along with formal semantics to use an additional glossary of terms.
An important advantage of OWL is that it is based on a precise mathematical model description logic [7].
OWL place in Semantic Web Concepts stack presented in Fig. 7.
Picture 7 W3 consortium structure of the Semantic Web vision
· XML – offers the possibility of creating structured documents, but imposes on him any semantic requirements;
· XML Schema – XML Schema – определяет структуру XML документов и дополнительно позволяет использовать конкретные типы данных;
· RDF – provides an opportunity to describe the abstract data model, some objects and relations between them. Uses simple semantics of XML-based syntax;
· RDF Schema – allows to describe properties and classes of RDF - resources, as well as the semantics of relations between them;
· OWL – expands the descriptive capabilities of previous technologies. Allows you to describe the relations between classes (for example Nonintersecting), cardinality (eg "exactly one"), symmetry, equality, enumerated types of classes.
By the degree of expressiveness are three dialects of OWL
· OWL Lite – is a subset of the complete specification, providing minimally adequate means of describing ontologies. Designed to reduce the initial introduction of OWL. And also to simplify the migration to OWL thesauri and other taxonomies. It is guaranteed that the logical conclusion to the metadata with the expressiveness of OWL Lite runs in polynomial time (complexity of the algorithm belongs to the class P).
This dialect is based on the description logic ![]() .
.
· OWL DL – on the one hand provides maximum expressiveness, computational completeness (all of them are guaranteed computed) and complete decidability (all computations are completed in a certain time). But in this regard has strict restrictions, for example on the relationship of classes and the execution time of some queries on such data may require exponential runtime.
This dialect is based on the description logic ![]() .
.
· OWL Full – provides maximum expressive freedom, but gives no guarantees decidability. All structures developed based justified only feasible algorithm. It is unlikely that any reasoning software will be able to maintain full support for every feature of OWL Full.
Not match any description logic, so - as, in principle, is not resolvable.
Currently OWL language is a basic tool for describing ontologies.
Software (mobile, user) agents (SA)
In our SD SA is the program, acting on behalf of the user to perform independently gathering information for some, perhaps a long time while away entirely predictable environment. Also important feature is their ability to interact and cooperate with other agents and services to achieve the goal.
In contrast to the bots of search engines, which simply scans a range of WEB pages, the agents move from one server to another, ie at the sending server agent is destroyed, and the host is created with a full set of previously collected information. This model enables the agent to use the available servers, data sources that are not accessible through the WEB interface.
It is clear that at the server must be installed platform that enables the agent to accept and accommodate his requests. It is also important to pay attention to the security and integrity of agents. For this, the approach selected spaces in which the agent operates in a safe environment with limited rights and opportunities impact on the system.
In its implementation of the agents are usually divided into two categories according to the level of its freedom:
· Nointelligent agents – are inherently similarity function with a clearly defined number of parameters. It is strictly intended to perform a specific task in a strictly defined conditions.
· Intelligent agents – are free to choose the technology to be used in each case to solve the problem. Often such programs are implemented by using neural networks, which allow the agent to constantly adapt to changing conditions.
Microformats
Microformats are an attempt to create a semantic markup entities in a variety of Web-pages are equally perceived as a good man and machine. Information in a microformat does not require the use of additional technology or the namespace in addition to the simple (X) HTML. Microformat specification, it is simply an agreement on standards for naming classes of elements of registration page to enable stored in each of the relevant data.
To illustrate analyze the format of hCalendar.
This microformat is a subset of the iCalendar format (RFC 2445) and is intended to describe the dates of future or past events to provide opportunities for their automatic aggregation of search agents.
<div class="vevent">
<a class="url" href="http://www.web2con.com/">
http://www.web2con.com/
</a>
<span class="summary">
Web 2.0 Conference
</span>:
<abbr class="dtstart" title="2007-10-05">
October 5
</abbr>
-
<abbr class="dtend" title="2007-10-20">
19
</abbr>
,at the
<span class="location">
Argent Hotel, San Francisco, CA
</span>
</div>
In this example describes the establishment of the root class of the container with the date (class = "vevent") and relating to an event a certain date in the standard ISO date format.
Currently the most common microformats are
· hAtom - newsletters format;
· hCalendar - compiling a calendar of events and description;
· hCard - description of the people, companies, places;
· hResume - format for resume description;
· hReview - reviews implementation;
· XFN - way to specify relationships between people;
Modern Trends in Development of ontologies
Preparation of ontologies using an expert approach is very slow and expensive process, and although the result may be very good, but the vast majority are using automatic classifiers that build ontologies according to available data. In this way many troubled places, and therefore existing automatic classifiers are not of good quality and one of the options for increasing the accuracy of classification is the Ontology Aware Classifiers [9].
When using automatic methods of data mining (data-driven knowledge discovery) sometimes there is a need to investigate the information received from different points of view. This is especially important in scientific research, when the result of data analysis depends strongly on the used for submission to the ontology. In particular, it is one of the most important moments in the procedure of automatic learning classifier data based on their ontologies. For example, if the analyzed data in different parts of the attributes are represented with different accuracy (which is very common in real applications, for example, if the data was originally collected from various sources, with different terminology), then at the moment there is no algorithm that takes into account this and used different levels of ontologies for different parts of the data and work effectively with potentially inadequately specified data.
The following requirements are prerequisites for the establishment of a new generation of classifiers:
· require a simple, powerful and robusta classifiers;
· classifiers using abstract attributes often provide the most simple model of the separation of data;
· in the case of insufficient data score obtained on the basis of abstract attribute values are often more reliable than on the basis of primitive values.
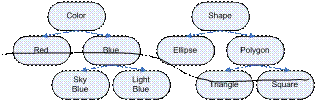
Picture 8 Part of ontologies for colors and descriptions of figures
In Fig. 8 can see examples of partially and fully defined shapes. For example, partially defined data such as (blue, ellipse), (sky blue, triangle), fully determined (light blue, square).
There is a method for creating a learning classifier templates based Attribute Value Taxonomies (AVT) in the presence of potentially insufficient data. The algorithm uses a decision tree and is called (AVT-DTL Attribute Value Taxonomies - Decision Tree Learning algorithm).
There is an ontology of colors (Fig. 8), and analyzed data, some attributes are described as blue, some like red, and some like a sky-blue. In this case, the algorithm produces a classification based on multiple levels of the ontology would be more accurate.
The classical method for constructing the classification tree at each step selects the most informative attribute, and declares it the node at the current iteration. In contrast, AVT-DTL for each iteration chooses not simply an attribute, and the level of taxonomy, in which he represented. This level is represented as a vector of numbers at all levels involved in the classification taxonomies. Then, on the basis of all created this way vectors created lower bound on the minimum values of the vectors for each taxonomy. Finally, checks on the adequacy of informativeness obtained constraints.
Define some terms
· AVT(A) – taxonomy of attribute А;
· Leavs(AVT(A)) – set of all possible values of А;
· all internal, intermediate nodes called abstract;
· cut is called an imaginary line abstraction taxonomy, for example (red, blue), (red, sky blue, turquoise).
To achieve each leaf, there is one path T, which can be represented as a set of paths to all the parent nodes T = {T1,T2,..Ti}, where Ti = AVT(Ai).
Also, in addition, the following operations on the taxonomy of Ti associated with the attribute Ai:
· prim (Ti)=Leaves(AVT(Ai)); number of nodes in the i-th taxonomy;
· depth(Ti , v(Ai)); length of the path from the root to the value of the i-th attribute taxonomy;
·
leaf(Ti , v(Ai)); boolean value, true if the
i-th attribute in the taxonomy of the Ti is a leaf, ie v(Ai)
![]() Leaves(Ti).
Leaves(Ti).
It is believed that the attribute is completely
defined if it has a value of one of the leafs of taxonomy A ![]() Leaves(AVT(A)), otherwise the attribute is defined
partially.
Leaves(AVT(A)), otherwise the attribute is defined
partially.
These are declared completely defined if each
attribute has the most complete description: ![]()
![]() .
.
The considered algorithm is a search from top to bottom over the space of hypotheses for constructing a decision tree. The algorithm gives preference to the division on how to more abstract (close to the root) attributes. This allows for each attribute to choose its level of abstraction in the taxonomy.
In the description of the algorithm uses the following definitions:
· A={A1, A2, …, An} ordered set of attributes.
· T={T1, T2, …, Tn} taxonomies set.
· C={C1, C2, …, Cm} set targets, which are mutually disjoint classes.
· ψ(v, Ti) - many descendants of the node corresponding to the value v in the taxonomy Ti.
·
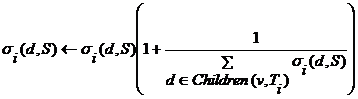 |
Children (v, Ti) - many descendants of the node v in the taxonomy Ti.
· Λ(v, Ti) – list of ancestors, including the root, for v in Ti.
· σi(v, S) – number of occurrences of value v of attribute Ai in a training set S.
· Counts(Ti) – tree whose nodes contain numerical values of attributes in the taxonomy Ti.
·
![]() - vector of values (also called the boundary AVT),
consisting of the values of nodes of S, where node
- vector of values (also called the boundary AVT),
consisting of the values of nodes of S, where node ![]() indicates
the node value Ti of attribute Ai.
indicates
the node value Ti of attribute Ai.
![]() true, only if
true, only if ![]() , and
, and![]() .
.
AVT-DTL algorithm works in the direction of AVT from the root of each tree to the leaves of trees and build solutions that use the most abstract attributes which are sufficiently informative to classify the training set, containing a potentially insufficient data. In its work on an algorithm, based on existing AVT, conducts a search algorithm, hill-climbing (in which each next node is selected by increasing its proximity to the decision) over the space of hypotheses about the options for constructing a decision tree.
The algorithm consists of two main steps:
1. Calculation of weights on the basis of AVT.
2. Building a decision tree, based on this weights.
More information about each of the steps.
1. Calculation of weights on the basis of AVT consists of the following:
a. Creating a root element, setting a training set S, completing the set PS={A1, A2, …, An} so that each of the elements of the vector used the value of the corresponding taxonomy T1, T2, …, Tn.
b. Initialize the calculation of weights based on the analysis of training data;
i.
Accumulation of weights associated
with each value of each attribute of the training set. Thus each ![]() calulated σi(v, S) for
each taxonomy.
calulated σi(v, S) for
each taxonomy.
ii.
For each![]() updated weights of all elements of the parent if the
previous step for the i-th node was received zero. The result is a tree Counts(Ti).
updated weights of all elements of the parent if the
previous step for the i-th node was received zero. The result is a tree Counts(Ti).
iii.
For each![]() and for all incomplete attribute
value v in each case Ij
and for all incomplete attribute
value v in each case Ij ![]() S, recursively calculates the weight values for all
descendants v in taxonomy Ti at the base on Counts(Ti) and rebuilds Counts(Ti). Thus,
for each d from ψ(v, Ti), rebuilds σi(d,
S) using this formula:
S, recursively calculates the weight values for all
descendants v in taxonomy Ti at the base on Counts(Ti) and rebuilds Counts(Ti). Thus,
for each d from ψ(v, Ti), rebuilds σi(d,
S) using this formula:
(1)
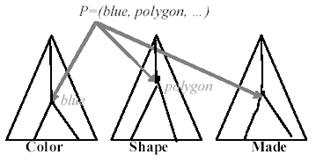 |
Picture 9 Sample of the vector pointer p
As an illustration, in Fig. 8 represents a vector pointing to the two attribute values blue and polygon for two taxonomies used for the approximately following rule: If (Color=blue & Shape=polygon &…) then Class =+.
2.
Building a decision tree, based on
the weight consists of the following operations (![]() :
:
a.
If every element of the training
set S is marked as Ci, then returns Ci, when returns Ci,
otherwise if ![]() when there is a need to create the final (leaf)
element (Stopping Criterion).
when there is a need to create the final (leaf)
element (Stopping Criterion).
b.
For each pointer![]() in vector
in vector ![]() do:
do:
i.
Check each part of a null value
with a partially specified attribute v to attribute Ai
with pointer ![]() . If depth(Ti , Pi(S)) < depth(Ti
, v), a partially unspecified value is treated as a fully qualified and
sent to the appropriate level of decision tree with root
. If depth(Ti , Pi(S)) < depth(Ti
, v), a partially unspecified value is treated as a fully qualified and
sent to the appropriate level of decision tree with root ![]() . Otherwise replace v with probability d
(element Children (v, Ti)) in accordance with the distribution of weights
associated with the Children (v, Ti) by the following
rule:
. Otherwise replace v with probability d
(element Children (v, Ti)) in accordance with the distribution of weights
associated with the Children (v, Ti) by the following
rule:
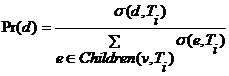 (2)
(2)
ii. Calculates the entropy of S on the basis of its separation Children (pi(S), Ti).
c.
Selecting best pointer ![]() в
в![]() to, this division of S provided
the maximum information gain.
to, this division of S provided
the maximum information gain.
d.
Separation of set S into subsets ![]() using data from Children
(pa(S), Ti).
using data from Children
(pa(S), Ti).
e.
Expansion PS to
obtain a new pointing vector of the subset ![]() by changing the pointer Pa(S) to value of attribute Ai from corresponding subset Sj
by changing the pointer Pa(S) to value of attribute Ai from corresponding subset Sj
![]() .
.
f.
For each ![]() do
do ![]() .
.
Description of evaluation algorithm
To confirm the effectiveness of this algorithm, a comparative test on the same sample with another, the most popular at the moment algorithm C 4.5.
The results proved the effectiveness of the algorithm, particularly important was the marked increase in the quality of the final classifier constructed from the sample with a high percentage of missing data. The final payoff is within 5% -30% increase in the efficiency of classification. Also noted that by AVT-DTL algorithm classifying trees containing fewer nodes and more compact, allowing a gain in the amount of resources required for their use.
Conclusion
At the time of melon, it is difficult to predict what will be the system of data exchange in the future, but the directions of development are laid right now and their effectiveness depends on many things.
This paper describes the basic technology allows you to create complex systems that can be used effectively as human beings and machines. In the stack concepts Semantic WEB at various levels is a large number of different technologies, but sharing their application would lead to synergies.
So - as the effectiveness of technologies for each level of the stack affects the whole system, then considered the second part of the algorithm AVT-DTL improving the quality of automatic qualifiers in the end will increase the effectiveness of the Semantic Web.
About the autors
Pavel Osipov Mg.Sc.Eng. Ph.d. student, Institute of Information Technology, Riga Technical University. He received his masters diploma in Transport and Telecommunications Institute, Riga. His research interests include web data mining, machine learning and knowledge extraction.
Arkady Borisov, Dr.habil.sc.comp.,Professor, Institute of Information Technology, Riga Technical University, 1 Kalku Street , Riga LV-1658 Latvija, e-mail: arkadijs.borisovs@cs.rtu.lv.
References
1. Main page of W3 consortium, Semantic Web ideology creator http://www.w3.org/2001/sw/.
2. Cory Doctorow Metacrap: Putting the torch to seven straw-men of the meta-utopia http://www.well.com/~doctorow/metacrap.htm.
3. Main microformats ideology site http://microformats.org/.
4. Main page of W3 consortium, Web Ontology Language for Services http://www.w3.org/Submission/2004/07/.
5. Mai page of W3 consortium, Resource Description Framework http://www.w3.org/Submission/2004/07/.
6. Main page of W3 consortium, Web Ontology Language (OWL) http://www.w3.org/2004/OWL/.
7. Baader F., Horrocks I., Sattler U., Description Logics as Ontology Languages for the Semantic Web // Berlin: Springer ISSN 0302-9743, February 2005. - P. 228-248.
8. Main page of microformats community http://microformats.org/.
9. Zhang J., Learning ontology aware classifiers // Dissertation of the requirements for the degree of DOCTOR OF PHILOSOPHY / Iowa State University 2005
 Наверх
Наверх
 Книги
Книги
